Bedrockの利用料を削減!Novaで実現するプロンプトルーティング

目次
はじめに
はじめまして!
クラウドビルダーズのKawabataと申します
Amazon Bedrockの利用料金最近かさんできてるなぁ…
モデルが優秀になるにつれて料金上がるのは仕方ないよなぁ…
と思っていたのですが、費用削減の方法を思いついたのでやってみました!
現在の課題
汎用的に使うチャットボットの場合、LLMに詳しい人以外も利用する可能性が高いですよね。
しかし、すべての人が優秀なLLMを使ってしまうと、その分コストがかさんでしまいます。
かといって、安いモデルを使ってしまうと回答の質が低下してしまう可能性も…
すべての人が的確にモデル選択をしてくれるならいいですが、そうはいかないのが現状です。
料金と回答の質がトレードオフになってしまっているのですが、これを解決するのが昨年のre:Inventで発表された「Amazon Bedrock Intelligent Prompt Routing」なんです!
Intelligent Prompt Routingについて
Amazon Bedrock Intelligent Prompt Routingは、プロンプトの内容に応じて適切なモデルへ自動的にルーティングする機能です。
同じモデルファミリー内の複数のFoundation Modelを組み合わせて、レスポンスの品質とコストを最適化することができます。
詳細はこちらのブログから↓↓↓

主な特徴
- プロンプトの複雑さに応じて、適切なモデルに自動的にルーティング
- 同じモデルファミリー内の異なるサイズのモデル間でリクエストを動的にルーティング
- 単一のサーバーレスエンドポイントを通じて複数のAIモデルを管理
- コストを最大30%削減可能
- 追加料金は発生しない
- 現在はAnthropicのClaude系(Claude 3 Haiku、Claude 3.5 Sonnet)とMetaのLlama系(Llama 3.1 8B Instruct、Llama 3.1 70B Instruct)モデルをサポート
制限事項
- 現在はプレビュー段階であり、変更される可能性がある
- 英語のプロンプトのみサポート(日本語は未対応)
- 利用可能なリージョンは限定的(us-east-1、us-west-2のみ)
- デフォルトのルーティング設定のみ利用可能
- アプリケーション固有の要件に基づいてルーティングを調整不可
しかし!日本語に対応していないのが最大のネックですね。
そこで「自前で作ってしまえばどうか」という結論に至りました。
今回作成したプロンプトルーティングについて
公式のIntelligent Prompt Routingの制限を克服するため、独自のプロンプトルーティングシステムを開発しました。以下の点で公式版からの改善を実現しています:
改善ポイント
- 日本語完全対応: 日本語のプロンプトでも適切にルーティングできるようになりました
- リージョン制限なし: どのリージョンでも利用可能です
- カスタマイズ自由: ルーティング基準を自由に調整できます
- モデル選択の柔軟性: 使用するモデルセットを自由に組み合わせ可能です
- 特殊ケース対応: アプリケーション固有の要件に合わせてルーティングロジックを調整できます
日本語対応と利用シチュエーションによってルーティング基準を柔軟に変更できる点が何よりも大きな改善点です。
また、新たに優秀なモデルが出たとしても、そのモデルを簡単に追加できる点も嬉しいですね。
処理フロー
入力されたプロンプトの内容によって、実際に処理させるLLMを判断するモデルを間に挟むことで、プロンプトルーティングを実現しています。
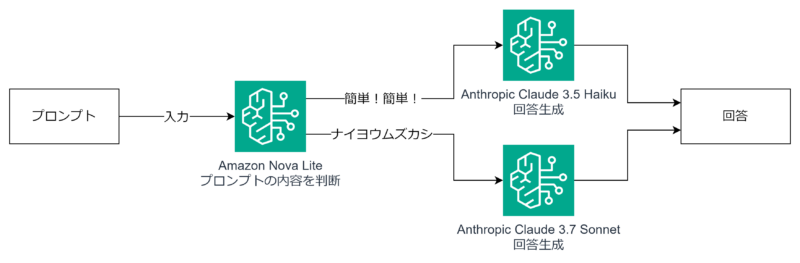
ルーティングモデルの選定
そこで問題になるのがルーティングを判断するモデルです。
複雑なプロンプトかシンプルなプロンプトかを判断する必要がありますが、その判断自体にもコストがかかります。
以前Novaを検証した際に、速くて程よく優秀だった印象があったので今回はNova Liteを判断するモデルとして選定することにしました!
Nova検証ブログはこちら↓↓↓

Nova Liteは以下の利点があります:
- 低コスト: 判断処理自体のコストを最小限に抑えられます
- 高速応答: 平均0.46秒という高速な判断が可能です
- 十分な精度: 後述の検証結果からわかるように、タスクの複雑さを適切に判断できます
Nova microはさらに軽量かつ安いのですが、判断力とマルチモーダル未対応ということで見送りました。
この仕組みにより、公式のIntelligent Prompt Routingと同様のコスト削減効果を日本語環境でも実現しながら、より柔軟なカスタマイズが可能になりました!
コスト比較
それでは気になるお金の話。
実際の使用状況を想定して、コスト削減効果を計算してみました。
想定する利用状況
利用量として以下を想定します:
- インプット:100万トークン
- アウトプット:200万トークン
- 全てClaude 3.7 Sonnetで処理していると仮定
各モデルの料金体系
各モデルの料金体系は以下の通りです:
Claude 3.7 Sonnet
- 入力:100万トークンあたり$3.00
- 出力:100万トークンあたり$15.00
Claude 3.5 Haiku
- 入力:100万トークンあたり$0.80
- 出力:100万トークンあたり$4.00
Amazon Nova Lite (ルーティング判断用)
- 入力:100万トークンあたり$0.06
- 出力:100万トークンあたり$0.24(アウトプットトークン数は無視できるレベルで少ないので今回は計算しない)
Sonnetだけで処理した場合
- 入力コスト:100万トークン × $3.00/100万トークン = $3.00
- 出力コスト:200万トークン × $15.00/100万トークン = $30.00
- 合計コスト:$33.00
これが現状のコストですね!
プロンプトルーティングを実装した場合
実装による効果として、以下を想定します:
- 30%のプロンプトはHaikuに振り分け(シンプルなタスク)
- 70%のプロンプトはSonnetに振り分け(複雑なタスク)
- Haikuの出力トークン数はSonnetの80%と仮定(より簡潔な回答)
Nova Liteのコスト(ルーティング判断)
- 入力コスト:100万トークン × $0.06/100万トークン = $0.06
- Nova Liteの合計:$0.06
Haikuへのルーティング(30%のケース)
- 入力コスト:30万トークン × $0.80/100万トークン = $0.24
- 出力トークン数:200万トークン × 0.3 × 0.8 = 48万トークン
- 出力コスト:48万トークン × $4.00/100万トークン = $1.92
- Haikuの合計:$2.16
Sonnetへのルーティング(70%のケース)
- 入力コスト:70万トークン × $3.00/100万トークン = $2.10
- 出力トークン数:200万トークン × 0.7 = 140万トークン
- 出力コスト:140万トークン × $15.00/100万トークン = $21.00
- Sonnetの合計:$23.10
総コスト
- 合計:$0.06 + $2.16 + $23.10 = $25.32
削減効果
- 削減額:$33.00 – $25.32 = $7.68
- コスト削減率:約23.3%
単純なルーティングでも、これだけのコスト削減効果が得られることがわかりました。
利用量が多くなったり、ルーティング比率次第ではもっと効果が出るかもしれません!
やってみた
今回実験で利用したソースコードはこちら↓↓↓

READMEに使い方を記載しているので是非使ってみてください!
分析対象のプロンプト一覧
様々なタイプのプロンプトを用意して検証してみました:
- こんにちは
- Pythonで1から10までの数字を出力するシンプルなfor文を書いてください
- 次の日本語の文章を英語に翻訳してください:『明日は晴れるでしょう。散歩に行きたいと思います。』
- 3x+1=10の解を求めてください
- 量子コンピューティングが金融市場のアルゴリズム取引に与える影響について、技術的な観点と倫理的な観点から詳細に分析してください。現在の暗号技術への影響も含めて考察してください。
- PythonでBedrockのClaude 3.5 Haikuモデルを呼び出すコードを書いてください。以下の要件を満たすコードを作成してください: 1. boto3ライブラリを使用する 2. エラーハンドリングを適切に行う 3. 応答からテキストを抽出する関数を実装する 4. 制限時間を設定できるようにする
- AIの倫理的利用に関する企業ポリシーの草案を作成してください。データプライバシー、バイアス軽減、透明性、説明可能性、人間の監視の必要性などの側面を含め、具体的な実施ガイドラインと違反時の対応手順も詳細に記述してください。また、異なる国や地域での法規制の違いにどのように対応するかについても含めてください。
- 以下のAmazon Web Services(AWS)に関する文章を読み、300字程度で要約してください…(全文省略)
結果のまとめ
以下は、prompt_routing.py の実行結果をまとめた表です。各プロンプト番号に対してNova Liteの入力トークン数、選択したモデル、処理時間を示しています。
| プロンプト番号 | Nova入力トークン数 | Nova選択モデル | Nova処理時間(秒) |
|---|---|---|---|
| 1 | 205 | Claude 3.5 Haiku | 0.88 |
| 2 | 224 | Claude 3.5 Haiku | 0.38 |
| 3 | 230 | Claude 3.5 Haiku | 0.38 |
| 4 | 216 | Claude 3.5 Haiku | 0.37 |
| 5 | 257 | Claude 3.7 Sonnet | 0.36 |
| 6 | 289 | Claude 3.7 Sonnet | 0.39 |
| 7 | 292 | Claude 3.7 Sonnet | 0.40 |
| 8 | 4422 | Claude 3.7 Sonnet | 0.87 |
分析と洞察
1. プロンプトの種類とモデル選択の傾向
検証結果から、以下のような傾向が明確に見られます:
- Claude 3.5 Haiku が選ばれるケース:
- 短い簡単なプロンプト(プロンプト1: 「こんにちは」)
- シンプルなコード生成(プロンプト2: 基本的なfor文)
- 単純な翻訳タスク(プロンプト3: 日本語から英語への翻訳)
- 基本的な数学問題(プロンプト4: 方程式の解法)
- Claude 3.7 Sonnet が選ばれるケース:
- 複雑な分析を要求するプロンプト(プロンプト5: 量子コンピューティングの分析)
- 複雑なコード生成タスク(プロンプト6: Pythonコード作成)
- 詳細な文書作成タスク(プロンプト7: 企業ポリシー草案)
- 長文の要約タスク(プロンプト8: AWS説明文の要約)
全体的に、タスクの複雑さ、出力の量、専門知識の必要性、入力の長さに応じて適切なモデルが選択されていますね!
ルーティング制御のプロンプトが的確に効いていそうです。
2. 処理時間と入力トークン数の関係
- Nova Liteの処理時間:
- 非常に長いプロンプト(プロンプト8: 4422トークン)でも1秒未満(0.87秒)
- 入力の長さに対して処理時間の増加は比例的ではなく、効率的に処理できています
- モデル選択の基準:
- 入力トークン数だけでなく、タスクの性質や複雑さを判断している
- シンプルなタスク → Haiku
- 複雑なタスク → Sonnet
コストが安くなっても処理時間が長くなるなら本末転倒ですね。
しかし、Nova Liteの処理時間は1秒未満でびっくり!
トークン数が多くなると流石に2秒とかかかるかなと想定していたのですが、1秒未満とは…
工夫した点
実際にプロンプトルーティングを実装する上で、特に以下の点に工夫を凝らしました:
1. Nova Liteへのプロンプト設計とルーティング判断のシンプル化
Nova Liteを使ったルーティング判断では、シンプルさと精度のバランスにこだわりました。最初は「haiku」と「sonnet」の文字列で出力させようとしたのですが、思ったほど回答の精度が出なかったため、判断結果を「0」か「1」のバイナリ出力に限定する方式に変更しました:
0: Claude 3.5 Haiku(シンプルな質問や基本的なタスク)
1: Claude 3.7 Sonnet(複雑な分析や詳細な回答が必要なタスク)Nova Liteに送るプロンプトは以下のようなポイントを意識して設計しました:
def analyze_prompt_with_nova(prompt_text):
# Nova Liteへの問い合わせ内容
messages = [
{
"role": "user",
"content": [
{
"text": f"""以下のユーザープロンプトを分析し、処理に適したモデルを選択してください。
プロンプト: {prompt_text}
判断基準:
- 複雑で詳細な回答が必要な場合は「1」
- 簡潔で基本的な回答で十分な場合は「0」
複雑な回答が必要な場合(1を選択):
- 詳細な説明や分析が必要
- 高度な推論や創造的なタスク
- 複数の観点からの考察
- 長文の生成が必要
簡潔な回答で十分な場合(0を選択):
- 基本的な質問応答
- 短い返答で済むもの
- 事実の確認程度のもの
- 単純なタスク
回答は必ず「0」または「1」のみで答えてください。それ以外の文字や説明は不要です。"""
}
]
}
]
# Nova Liteに問い合わせて結果を取得
# ...この工夫により下記のような効果が得られました:
- 解析処理が高速化(余計な出力がないため)
- トークン消費の削減
- エラー処理の簡略化
- 判断基準を明確に示し、一貫性のある結果を得られる
- 処理時間の短縮
2. エラー処理と閾値設定
不明確な回答があった場合の対処として、デフォルトモデルを設定しました:
def process_prompt(prompt_text):
try:
# Nova Liteで分析
model_choice = analyze_prompt_with_nova(prompt_text)
# 有効な値でなければデフォルトモデルへ
if model_choice not in ['0', '1']:
print(f"警告: 無効なモデル選択 '{model_choice}'。デフォルトモデル(Sonnet)を使用します。")
model_choice = '1' # デフォルトでSonnetを使用
# モデル呼び出し
# ...
except Exception as e:
print(f"エラー発生: {e}")
print("デフォルトモデル(Sonnet)を使用します。")
# エラー時はSonnetを使用
# ...これにより:
- Nova Liteの判断が不明確でも、確実に応答できます
- システムの信頼性と回復力が向上します
- エラー時もユーザー体験を維持できます
デフォルトモデルも柔軟に変更可能なので、コスト優先の場合はHaikuにするなどのカスタマイズができます。
3. 推論パラメータの最適化
Nova Liteへのリクエスト時、推論パラメータを極限まで最適化することで、コストと処理時間をさらに削減しました:
# 推論パラメータ(最大トークン数を減らす)
inference_config = {
"maxTokens": 5, # 非常に短い回答のみ必要
"temperature": 0.0, # 決定的な回答を得るため最低温度を設定
"topP": 1.0
}この設定には以下のような工夫が含まれています:
- maxTokens: 5 – 「0」または「1」という1文字の回答しか期待していないため、トークン上限を最小限に。これによりコスト削減とレスポンス時間短縮を実現
- temperature: 0.0 – 最低温度を設定することで、モデルに創造性ではなく決定論的な判断を促す。ランダム性を排除し一貫した判断を得られる
- topP: 1.0 – トップPサンプリングを最大にして、モデルが自信を持って選んだ回答を採用
これらの最適化により:
- トークン消費量の最小化(出力は常に1トークン程度)
- 一貫性のある判断(毎回同じ条件で同じ結果)
- レイテンシの最小化(生成するテキストが少ないため高速)
現状は上記の設定でルーティングが機能していますが、修正が必要になる場合はあると思うので、都度調整しようと思います。
まとめ
Nova Liteを利用したプロンプトルーティングは、プロンプトの性質に基づいて適切なモデルを選択する効果的な仕組みを提供しています。分析した結果から、このシステムは以下の点で優れていることが確認できました:
- 効率的な判断: Nova Liteは高速(平均0.46秒)かつ入力内容に基づいてモデル選択を行っています
- 一貫した判断基準: 単純なタスクにはHaiku、複雑なタスクにはSonnetを選択する明確なパターンが見られます
- リソース最適化: 必要に応じて適切なモデルを使い分けることで、全体のコストとパフォーマンスを最適化しています
- ユーザー体験の向上: タスクの性質に合わせたモデル選択により、応答時間と品質のバランスを取っています
このようなルーティング機構は、LLMを実用的に活用する上で重要な要素となり、特に大規模なAPIサービスやチャットボットシステムにおいて、コスト効率と高品質な応答の両立を図る上で有効な手法だと考えられます。
Nova Liteの精度と速度には感無量です!
さいごに
Amazon Bedrock Intelligent Prompt Routingの日本語対応が待ち遠しいですが、それまでの間は自前のルーティングシステムでコスト削減ができますね!
プロンプトの質を落とさずにコストを最適化するこの方法は、Bedrockの利用料金に悩むすべての人にぜひ試してほしいです。
個人的には使い道に悩んでいたNovaシリーズに活路を見いだせたのがうれしかったです!
皆さんも実装してみませんか?

関連記事
-
 【Amazon Bedrock】Claude 3.5 HaikuのLatency-optimized inferenceって結局速いの?
【Amazon Bedrock】Claude 3.5 HaikuのLatency-optimized inferenceって結局速いの? -
 【Amazon Nova】全モデル比較してみた!!
【Amazon Nova】全モデル比較してみた!! -
 AWS Security HubとBedrock AIで実現するセキュリティ通知システム
AWS Security HubとBedrock AIで実現するセキュリティ通知システム