Glueを利用し、S3にアップロードしたCSVファイルをParquet形式に変換する

目次
はじめに
こんにちは!スカイアーチHRソリューションズのiizakaです。
先日、AWS Certified Data Engineer – Associate【DEA-C01】認定試験を受けてきました。
試験の中でこんな問題がありました。
“CSV形式のデータをS3データレイクに取り込む必要がある。コスト効率が良いデータセットへのクエリの方法は、Glueを使いParquet形式でデータレイクに取り込むジョブを構成すること”
というような趣旨でした。
Glueを利用したことないけど、Glueで変換できるんか?Parquet形式ってなんだ?
と気になったので実際にやってみました。
整理
やりたいこと
S3バケットへCSV形式のファイルをアップロードする。
自動的にCSV形式のファイルをParquet形式に変換して保存する。
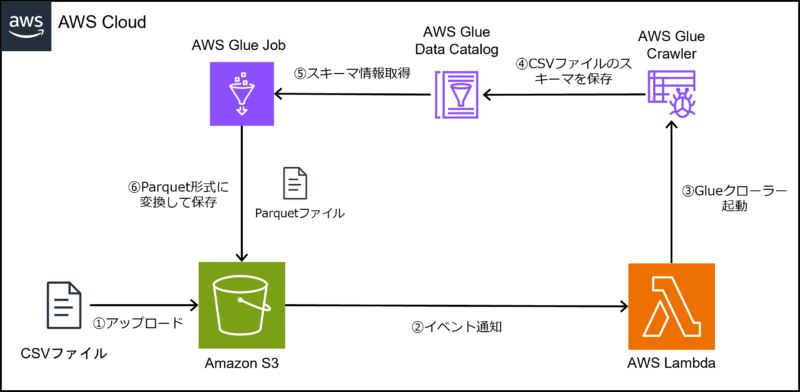
必要なリソース
① CSVファイルをアップロードするS3バケットの作成
② CSVファイルのスキーマを検出し、Parquet形式に変換するGlueジョブの作成
③ Glueジョブを実行させるLambda関数の作成
④ Lambda関数を実行させるS3イベント通知の設定
前提調査
AWS Glueとは
AWS Glueは、完全マネージド型のETL(Extract, Transform, Load)サービス。データの抽出、変換、およびロードのプロセスを簡素化および自動化するためのツールを提供し、データ統合や分析を効率的に行えるようにする。
主なコンポーネントは下記です。
◆Glueクローラー
データストア(S3バケット、RDS、DynamoDBなど)をスキャンしてデータのスキーマを自動的に検出し、Glueデータカタログにメタデータとして登録する。
◆Glueデータカタログ
データのメタデータを管理するための一元化されたリポジトリ。データセットのスキーマ情報やテーブル定義を格納し、ETLジョブやクエリ処理のためのデータの参照を容易にする。
◆Glueジョブ
ETL処理を実行するためのユニット。データの抽出、変換、ロードを自動化するスクリプトを実行する。ジョブは、Glueデータカタログからデータを読み込み、指定されたターゲットにデータを出力する。
◆Glueスタジオ
グラフィカルなユーザインタフェースを提供し、ETLジョブの開発、テスト、およびデプロイを容易にするツール。コードを書くことなく、ビジュアルインターフェースを使用してETLワークフローを設計できる。
Parquet形式とは
Apache Parquetプロジェクトによって提供されるカラム指向のデータストレージ形式。特にビッグデータ処理と分析のために設計されており、高い圧縮率と効率的なクエリ性能を提供する。
リソース作成
S3バケットの作成
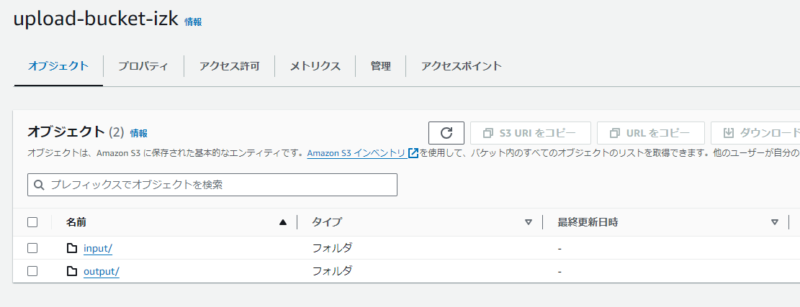
CSVファイルをアップロードするS3バケットを作成し、
inputフォルダ(CSVファイルのアップロード先)とoutputフォルダ(Parquetファイルの保存先)を作成します。
AWS Glueジョブの作成
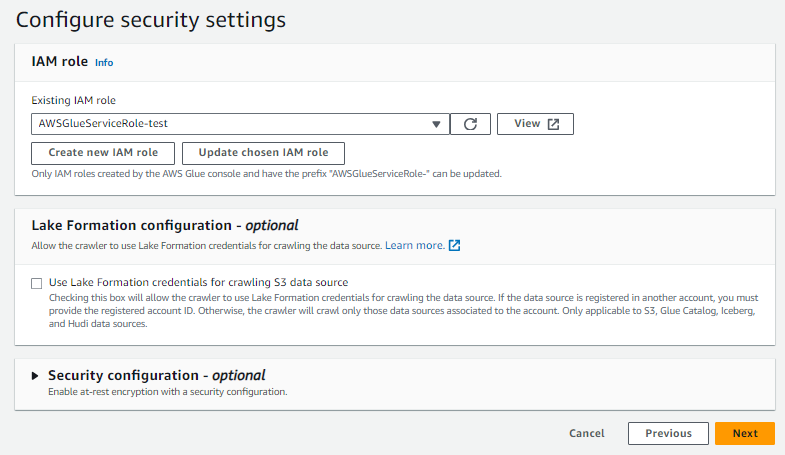
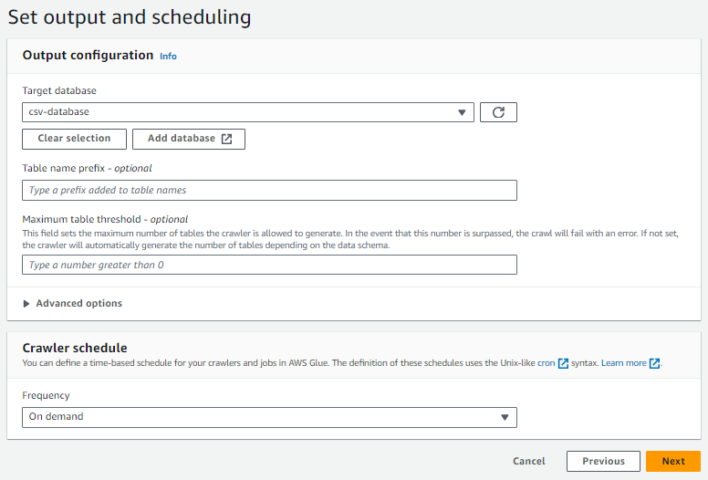
Glueクローラーの作成
GlueクローラーはS3バケット内のCSVファイルのスキーマを自動的に検出し、Glueデータカタログにメタデータを登録します。
Glueジョブの作成
GlueジョブはGlueデータカタログに登録されたCSVデータを読み込み、必要な変換を行い、Parquet形式でS3に保存します。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# データの読み込み
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "csv-database", table_name = "input", transformation_ctx = "datasource0")
# Parquet形式に変換
datasink2 = glueContext.write_dynamic_frame.from_options(frame = datasource0, connection_type = "s3", connection_options = {"path": "s3://upload-bucket-izk/output"}, format = "parquet", transformation_ctx = "datasink2")
job.commit()Lambda関数の作成
Glueジョブを実行させるLambda関数を作成します。
関数を作成し、下記コードを記述します。
import boto3
def lambda_handler(event, context):
glue = boto3.client('glue')
job_name = 'csv-to-parquet-job'
response = glue.start_job_run(JobName=job_name)
return {
'statusCode': 200,
'body': f'Glue job {job_name} started successfully.'
}S3イベント通知の作成
CSVファイルが該当のバケットにアップロードされた際にLambda関数を実行するイベント通知を作成します。
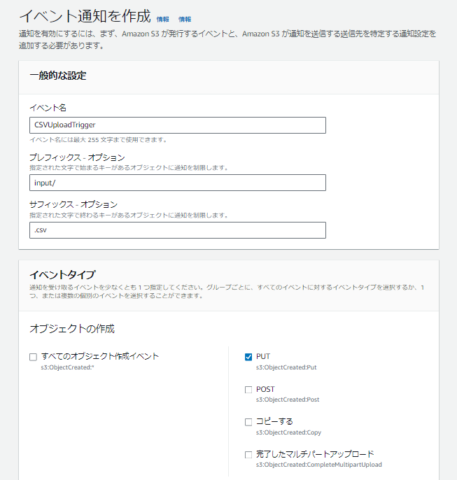
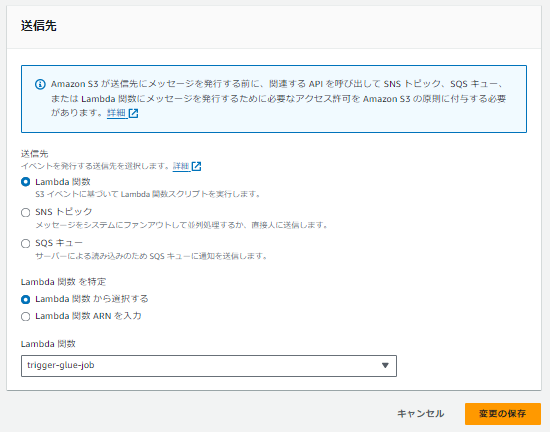
やってみる
今回の検証で使うCSVファイルは下記です。
名前,年齢,性別,出身
田中太郎,30,男性,東京都
田中花子,25,女性,神奈川県
田中一郎,35,男性,大阪府
田中美咲,40,女性,愛知県
田中次郎,28,男性,北海道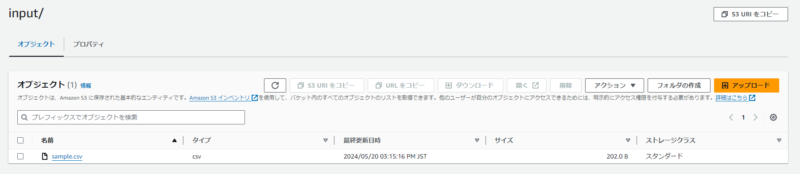
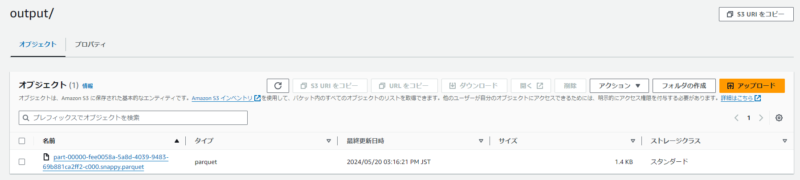
ちなみにparquet形式になったファイルをダウンロードして開こうとしましたがテキストエディタでは開けませんでした。
parquet形式はバイナリ形式であり人間が直接読むことはできない形式みたいです。
さいごに
今回の検証ではCSVファイルをGlueを利用してParquet形式に変換できることが確認できました。Glueに対しての理解が少し深まりました。次回はParquet形式のデータをAthenaを使って確認したり、Parquet形式に変換することによりどのくらいクエリ性能が向上するのか確認するところまで踏み込めたらなと思います。
