API GatewayとLambdaでChatGPTのAPIを使ってみる

目次
はじめに
こんにちは!CloudBuildersのアミです。
この記事はクラウドビルダーズ Advent Calendar 2024の2日目の記事です。
タイトルの通り、今回はAPI GatewayとLambdaでChatGPTのAPIを使ってみようと思います。
すぐできちゃいそう~と思って始めたもののしっかりつまずいたので、記事にすることにしました。
ちなみにChatGPTはサービス名なので、厳密にはChatGPTではなくOpenAIのAPIですが、本記事ではイメージのしやすさ重視でChatGPTのAPIと表現します。
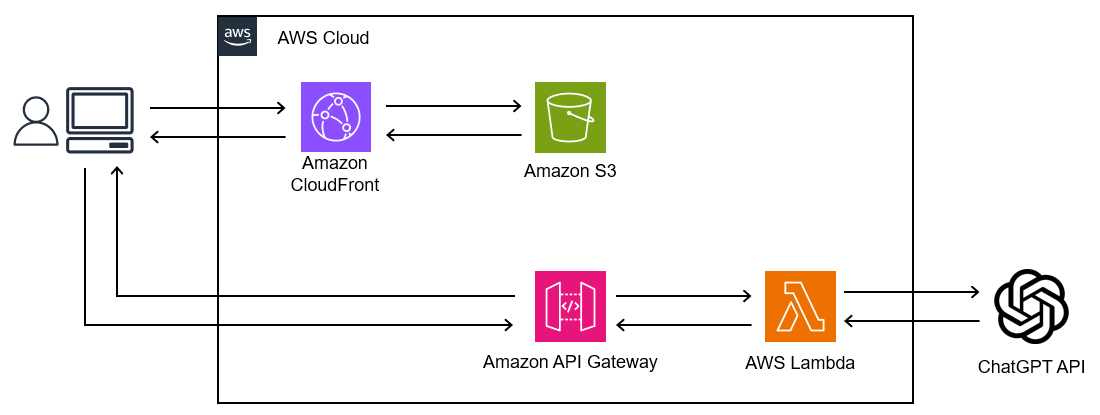
完成イメージ
フロント資材をCloudFront経由で取得して、クライアント側からAPIを呼び出します。
APIは直接API Gateway→Lambdaを経由して、LambdaからChatGPTのAPI呼び出します。
作ってみる
ChatGPT API (有料)
まずはChatGPTのAPIを使えるようにします!
必要な作業はAPI Keyの取得とクレジットの購入の2点です。
クレジットの購入はプリペイド方式で、最低でも5$の支払いが必要になります。でも5$だけで目一杯楽しめます!!
参考:料金
API Keyの取得
OpenAI developer platformにログインします。ChatGPTと同じアカウントでログイン可能です。
Dashboardの左ペインにあるAPI keysを選択して「+ Create new secret key」からAPI Keyの作成をします。
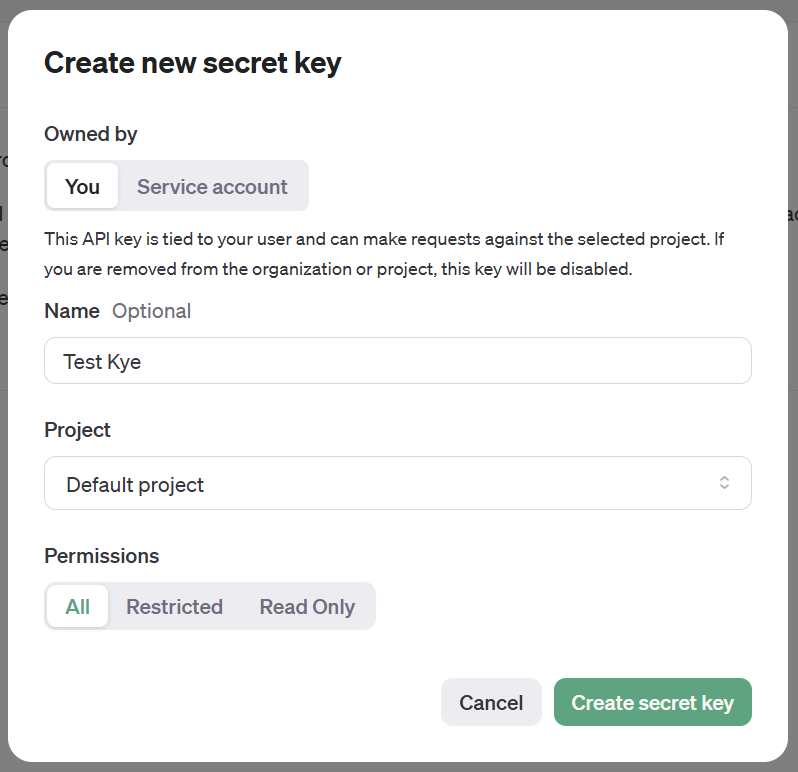
今回はほぼデフォルトで作成しました。
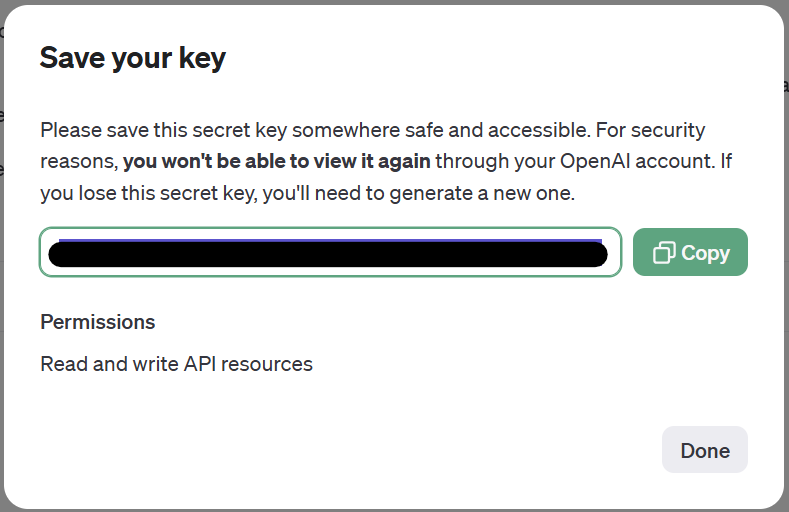
作成されたAPIキーは一度ウィンドウを閉じてしまうと再表示ができないので、忘れずに控えておきましょう。
クレジットの購入
画面右上の歯車マークを押して設定画面を開きます。
左ペインにあるBillingを選択して「Add payment details」からクレジットカードを登録します。
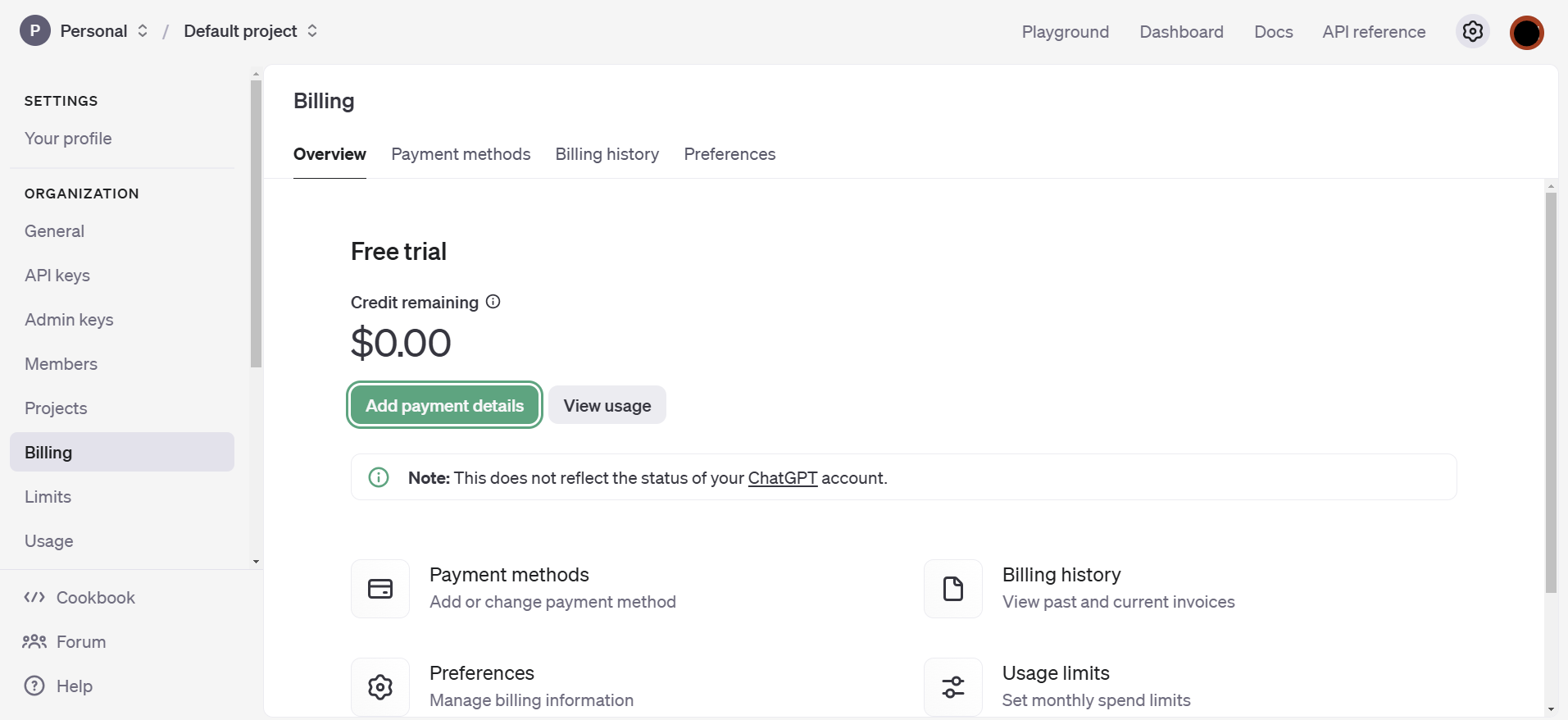
今回は個人利用なのでIndividualで登録しました。
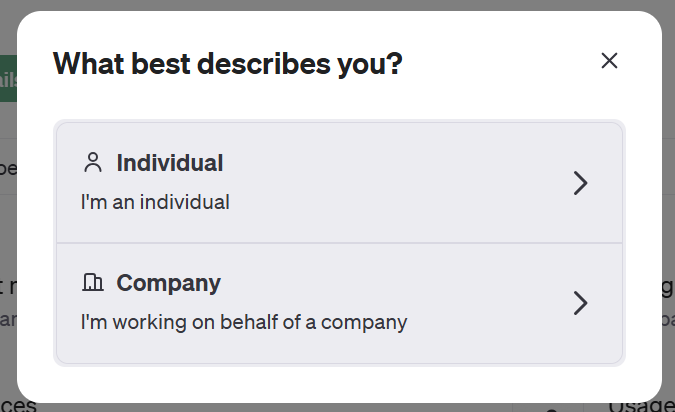
クレジットカード情報画面(Individual)はこんな感じです。
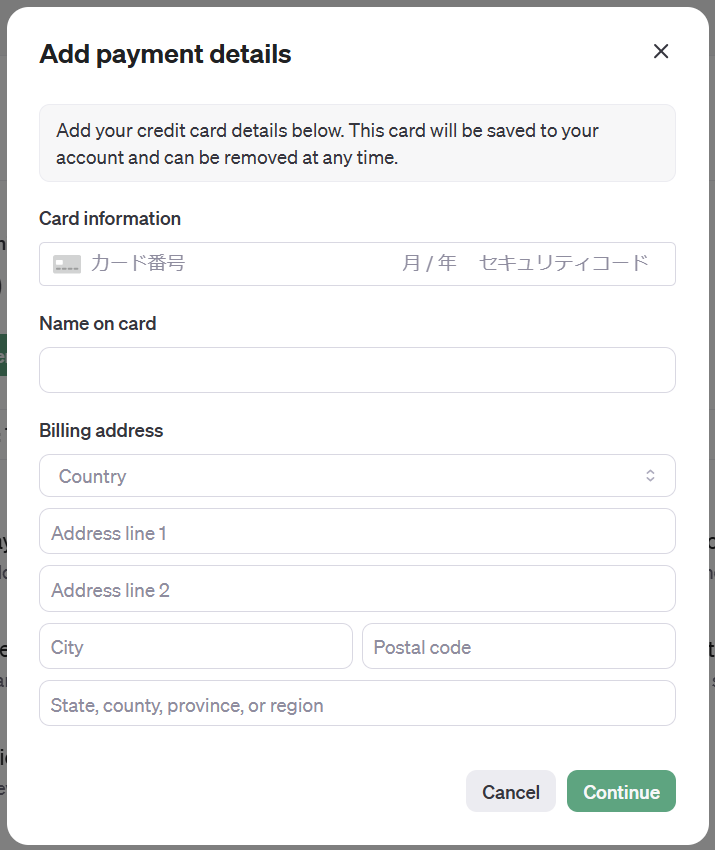
クレジットカードの登録をするとそのままチャージ設定に進みます。
最低金額の5$にしてオートチャージを無効化しました。
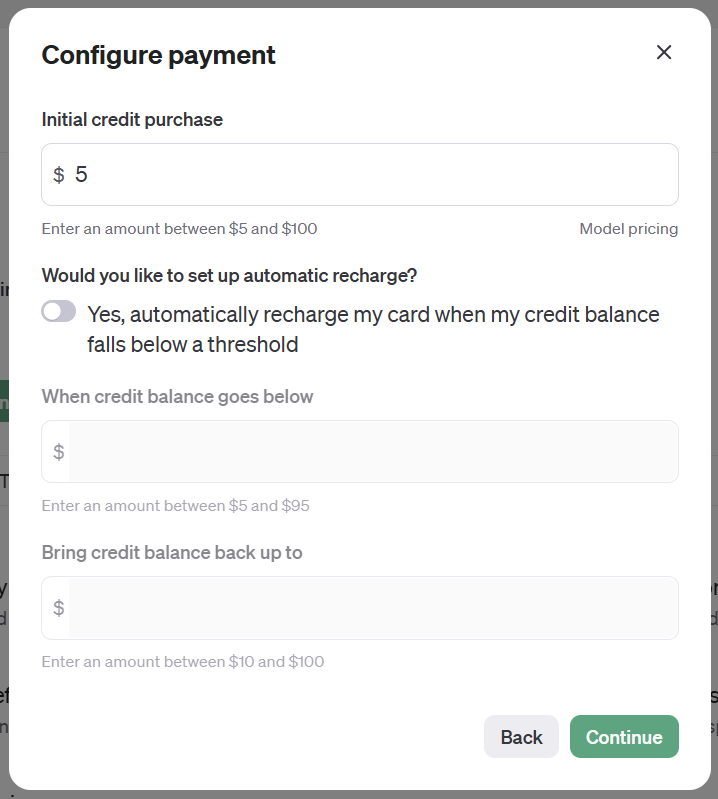
これでChatGPTのAPIを使うための準備ができました!
Lambda
続いてLambdaからChatGPTのAPIを呼べるようにしていきます。
Secrets Managerの設定
先ほど作成したAPIキーを使用するので、予めSecrets Managerに登録しておきましょう。
Lambdaのコードの中ではキーに設定した文字列(gpt_api_key)を使用します。
| 項目 | 設定値 |
|---|---|
| シークレットのタイプ | その他のシークレットのタイプ |
| キー/値のペア | キー:gpt_api_key 値:ChatGPTのAPIキー |
| 暗号化キー | aws/secretsmanager |
| シークレットの名前 | gpt_api_key |
Lambda Layer作成
あとはこのままLambda関数を作成して終わりだと思っていたのですが、いざ実行してみると下記エラーが発生。。。
[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': No module named 'openai'openaiというモジュールをLambdaレイヤーで自分で用意をする必要がありました。
AWS外のモジュールだからそりゃそうか~~と思いつつ、私は今回Lambdaで使用するPythonの実行環境がなく、今から用意するのも億劫だったのでどうしようか悩みどころでした。
結局、AWSのマネジメントコンソール上でCloudShellを使ってインストールして、一度ローカルに持ってきてLambdaレイヤーとして登録することにしました。
CloudShellで以下のコマンドを実行してopenaiのモジュールをインストール、zip化します。
mkdir python
pip install urllib3==1.26.16
pip install -t ./python openai==0.28
zip -r openai.zip ./pythonバージョン指定をしているのは、Lambda関数の実行時に下記のエラーが発生したからです。
[ERROR] APIRemovedInV1:
You tried to access openai.Completion, but this is no longer supported in openai>=1.0.0 - see the README at https://github.com/openai/openai-python for the API.
You can run `openai migrate` to automatically upgrade your codebase to use the 1.0.0 interface.
Alternatively, you can pin your installation to the old version, e.g. `pip install openai==0.28`無事にインストールができたら、CloudShellの右上にある「アクション」から「ファイルのダウンロード」を選択して、zip化したモジュールをダウンロードします。
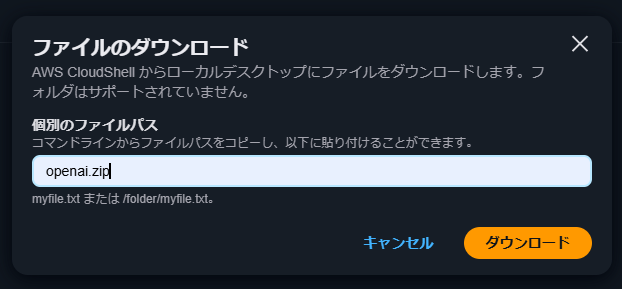
あとはLambdaレイヤーを作成してopenai.zipをそのままアップロードしたらOKです。
| 項目 | 設定値 |
|---|---|
| 名前 | Lambda_Layer_openai |
| アップロード方法 | .zip ファイルをアップロード(openai.zip) |
| 互換性のあるアーキテクチャ | x86_64 |
| 互換性のあるランタイムランタイム | Python 3.9 |
Lambda関数作成
やっとLambda関数の作成です(実際には先に作成していましたが)。今回は前述の通りPythonで作成しました。
実行ロールの内容は割愛させていただきますが、
・Secrets Managerの読み取り
・CloudWatch Logsのログストリーム作成、ログ送信
の許可が必要となります。
| 項目 | 設定値 |
|---|---|
| 関数の作成 | 一から作成 |
| 関数名 | LambdaDemo |
| ランタイム | Python 3.9 |
| アーキテクチャ | x86_64 |
| 実行ロール | 既存のロールを使用する (Secrets Manager、CloudWatch Logsの操作を許可したロールを使用) |
| タイムアウト | 30秒 |
Lambdaレイヤーも登録します。
| 項目 | 設定値 |
|---|---|
| レイヤーソース | カスタムレイヤー |
| カスタムレイヤー | Lambda_Layer_openai |
| バージョン | 1 |
ソースコードはこんな感じです。
chat_response内のパラメータでAPIの設定を変更できます。GPTのモデルはgpt-4にしました。
その他のパラメータもイイ感じに調整なんかしちゃったりしてLambda関数は完成です☺
import json
import boto3
import openai
# OpenAI APIキーをAWS Secrets Managerから取得
def get_openai_api_key():
secretsmanager = boto3.client('secretsmanager')
secret_name = "gpt_api_key"
response = secretsmanager.get_secret_value(SecretId=secret_name)
secret = json.loads(response['SecretString'])
return secret['gpt_api_key']
# ChatGPT APIを呼び出す
def lambda_handler(event, context):
# リクエストからテキストを取得
body = json.loads(event['body'])
original_text = body['text']
# Secrets ManagerからOpenAI APIキーを取得
openai.api_key = get_openai_api_key()
# ChatGPTで回答を作成
prompt = original_text
chat_response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "あなたは、どんなネガティブな話題もテンション高く、勢いでお祭り騒ぎに変える日本語アシスタントです。ため口で話し、絵文字をガンガン使って、ユーザーをとにかく盛り上げます!3~4文程度で、勢い第一、ちょっと適当でもOK。元気とノリで解決するスタイルを貫いてください!"},
{"role": "user", "content": prompt}
],
max_tokens=300
)
response_text = chat_response['choices'][0]['message']['content'].strip()
# 結果を返す
return {
'statusCode': 200,
'body': json.dumps({
'response_text': response_text
}),
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*'
}
}API Gateway
次はAPI Gatewayを作成します。
API作成
APIを作成します。特段変わった設定などはないですが、APIタイプは要件に応じてREST APIも検討すると良いかと思います。
| 項目 | 設定値 |
|---|---|
| API タイプ | HTTP API |
| API名 | TestAPI |
| エンドポイントのタイプ | リージョン |
ルートとメソッド設定
作成したAPIにルートとメソッドを設定します。今回は1つしか作成しないのでルートのパスは”/”で作っちゃいます。
| 項目 | 設定値 |
|---|---|
| メソッド | POST |
| ルート | / |
統合の作成
作成したルートにLambda関数を統合します。
| 項目 | 設定値 |
|---|---|
| この統合をルートにアタッチする | POST / |
| 統合タイプ | Lambda関数 |
| 統合ターゲット | (使用するLambda関数とリージョン) |
| アクセス許可を呼び出す | true |
CORS有効化
フロント資材とAPIを別でホストしているため、CORSを有効化します。
| 項目 | 設定値 |
|---|---|
| Access-Control-Allow-Origin | * |
| Access-Control-Allow-Headers | * |
| Access-Control-Allow-Methods | POST |
Auto Deployを設定していない場合はデプロイをして、API Gatewayも準備OKです!
S3
次はS3を作成してフロント資材を配置します。
バケット作成
ほぼデフォルト設定で作成しました。
| 項目 | 設定値 |
|---|---|
| バケットタイプ | 汎用 |
| バケット名 | (任意のバケット名) |
| オブジェクト所有者 | ACL 無効 |
| パブリックアクセスをすべて ブロック | オン |
資材アップロード
S3バケットが作成できたら、index.htmlとstyles.cssをアップロードします。
index.htmlは無駄に音声認識をいれちゃいました。
CSSは全部ChatGPTに作ってもらっちゃったので割愛します。。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>DemoApp</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<div class="container">
<div class="grid-container">
<div class="character-container">
<img src="https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjpVGU-kSsQfe4Oq3p68XJiZ-HJbCdL0ASRrnemQvmHo_v3bLheV2MUV05wlRQdURhVHkHVnW7K6VQRJajJIR1NuHyMOnngZ2S-NwO2OQU5YQC2Mosb6qop5aCtb4YB2mCQxhdhxgZc1ZVs/s800/dance_party_bus.png" alt="" class="character-image">
<div class="speech-bubble">
<p id="gpttext"></p>
</div>
</div>
</div>
<!-- 録音ボタン -->
<button id="start-record-btn">録音開始</button>
<!-- 音声認識結果表示 -->
<p id="transcribed-text"></p>
</div>
<script>
// 音声認識を実装(Web Speech APIを利用)
const startRecordBtn = document.getElementById('start-record-btn');
const transcribedTextElem = document.getElementById('transcribed-text');
const gptTextElem = document.getElementById('gpttext');
startRecordBtn.onclick = function () {
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
recognition.lang = 'ja-JP';
recognition.onstart = function() {
transcribedTextElem.textContent = "録音中...";
};
recognition.onspeechend = function() {
recognition.stop();
};
recognition.onresult = function(event) {
const transcribedText = event.results[0][0].transcript;
transcribedTextElem.textContent = transcribedText;
// GPT処理をバックエンドにリクエスト
fetch('https://xxxxxxx', { //API Gatewayで作成したエンドポイントを指定
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ text: transcribedText })
})
.then(response => response.json())
.then(data => {
gptTextElem.textContent = data.response_text;
})
.catch(error => {
console.error('エラーが発生しました:', error);
gptTextElem.textContent = "処理に失敗しました";
});
};
recognition.onerror = function(event) {
transcribedTextElem.textContent = "音声認識に失敗しました: " + event.error;
};
recognition.start();
};
</script>
</body>
</html>以上でS3もできました!もう一息です!
CloudFront
最後にCloudFrontを作成して完了です。
ディストリビューション作成
S3用のディストリビューションを作成します。キャッシュ周りの設定含め、ほぼデフォルトで作成しました。
| 項目 | 設定値 |
|---|---|
| オリジンドメイン | 作成したS3バケットを指定 |
| オリジンアクセス | Origin access control settings(デフォルト設定でOACを作成) |
| Origin Shieldを有効化 | いいえ |
| WAF | 無効 |
| デフォルトルートオブジェクト | index.html |
バケットポリシー設定
OACを作成するとS3バケットポリシーが生成されるので、S3に移動してバケットポリシーを追加で設定します。
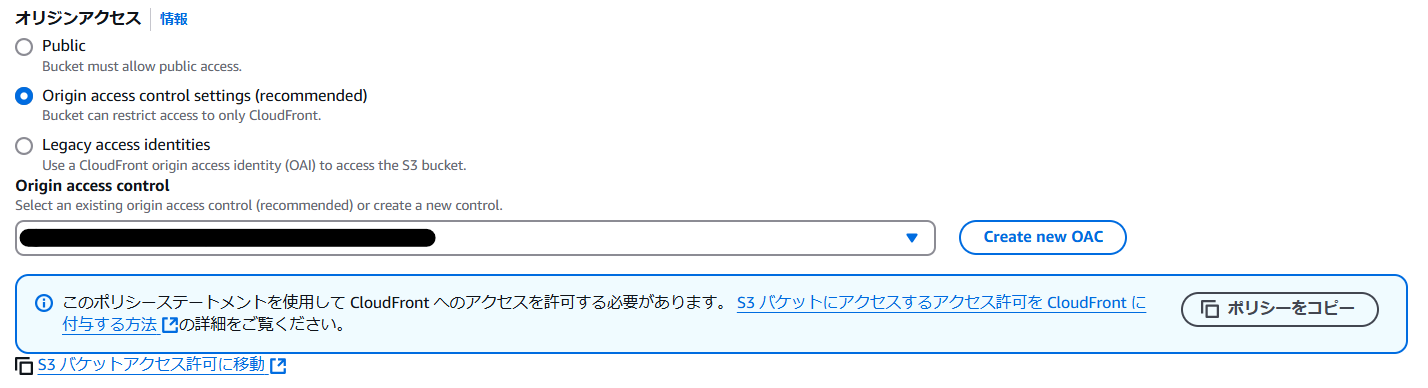
これでCloudFrontもできました!!
動かしてみる
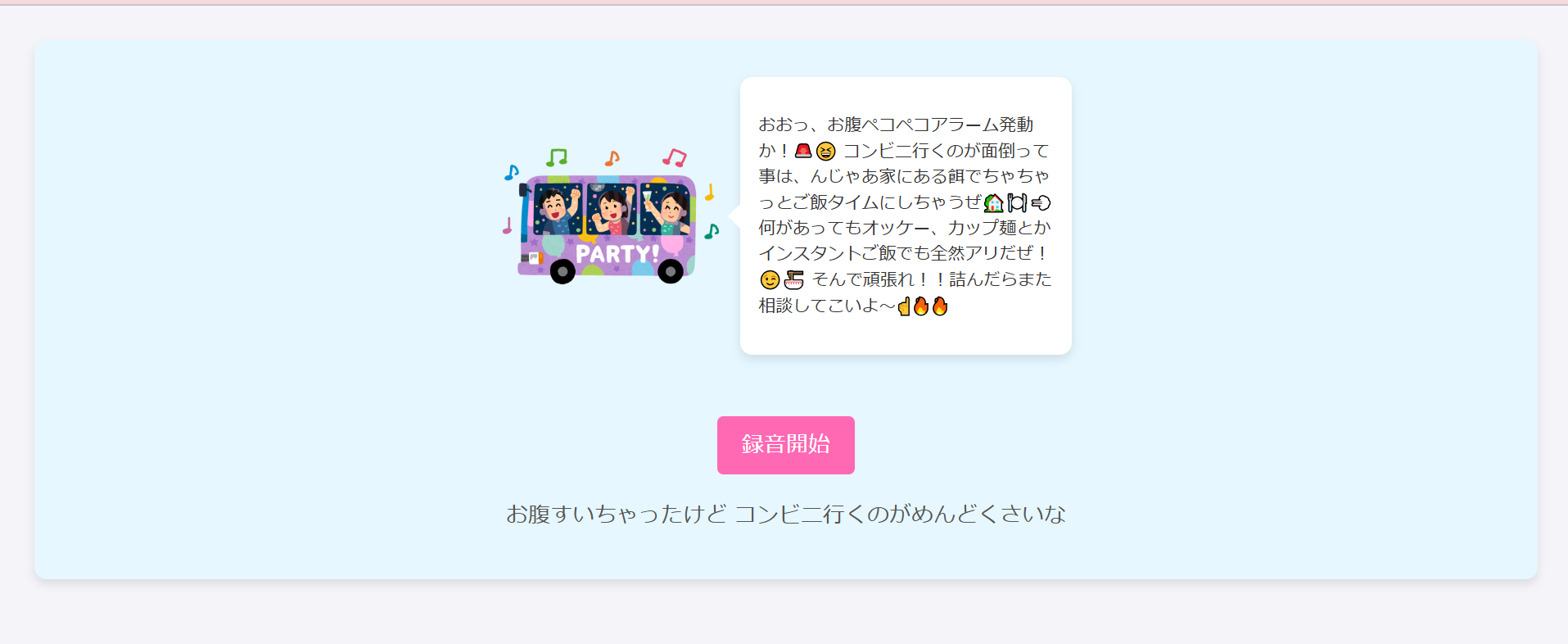
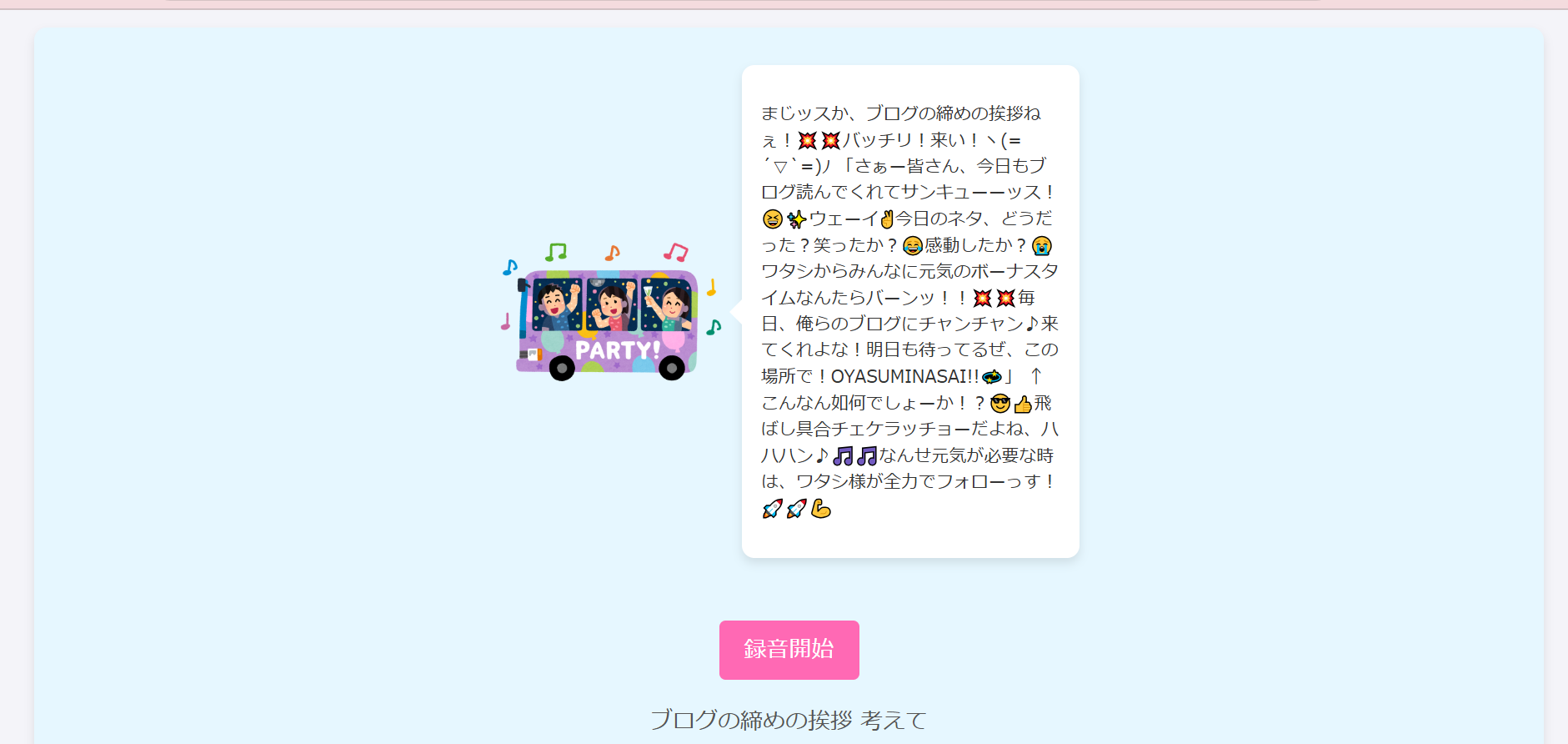
ディストリビューションドメイン名でアクセスして、実際に使ってみます!!
録音開始ボタンを押して話しかけると認識して処理してくれます。
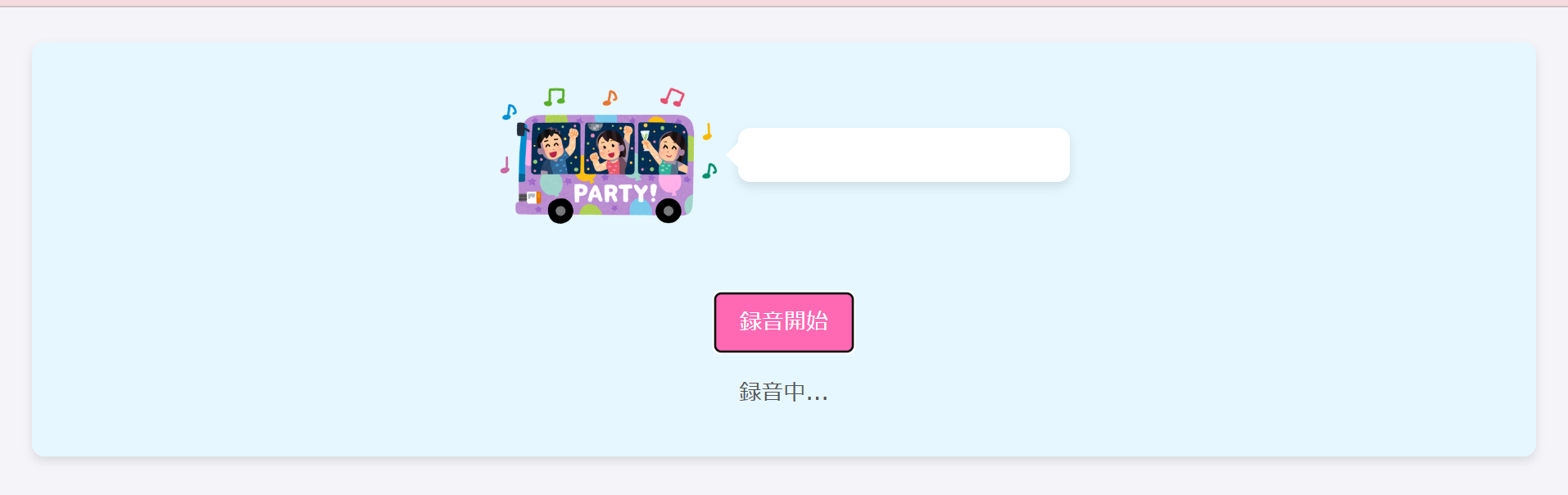
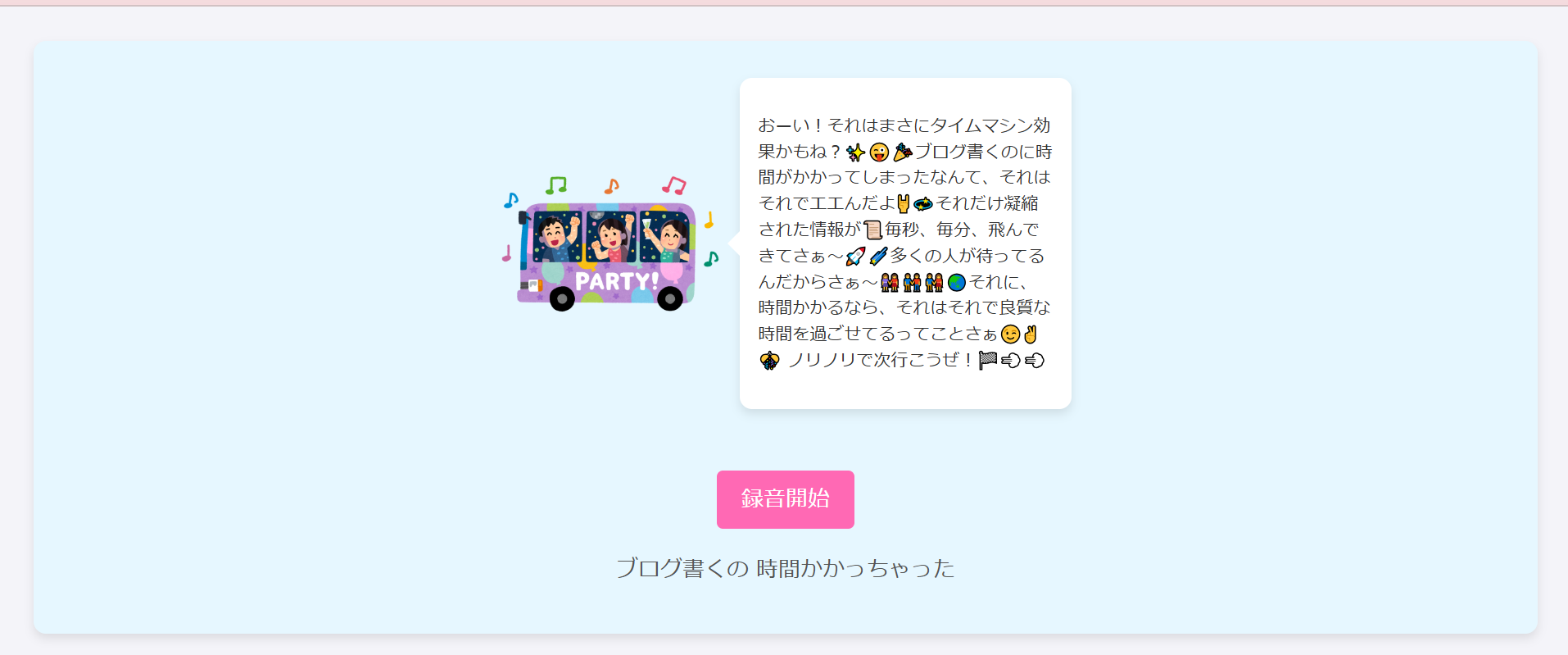
盛り上がってますね~~~
おわりに

関連記事
-
 SageMaker+APIGateway+Lambdaで作るサーバレスアプリケーション~③(完)
SageMaker+APIGateway+Lambdaで作るサーバレスアプリケーション~③(完) -
 SageMaker+APIGateway+Lambdaで作るサーバレスアプリケーション~外伝 Cognito認証
SageMaker+APIGateway+Lambdaで作るサーバレスアプリケーション~外伝 Cognito認証 -
SageMaker+APIGateway+Lambdaで作るサーバレスアプリケーション~②