【Lambda】LambdaからGoogle CloudのBigQueryにデータを挿入してみた
2024.12.08

この記事をシェアする
目次
はじめに
はじめまして!
クラウドビルダーズのKawabataと申します
先日、案件でLambdaを使ってCloudWatch LogsのログをBigQueryに挿入する機会がありまして
その時にGoogle Cloudの認証情報を利用してLambdaからBigQueryにデータを挿入する方法を知ったので
今回はその方法をブログに残しておきたいと思います
これは今後も利用することがありそう
やってみよう
こちらで利用したソースコードをGitHubに公開しています
SAMを使って簡単にデプロイできるのでぜひ!

Google Cloudでの認証情報の発行
- サービスアカウントの作成:
- IAMと管理 > サービスアカウントに移動
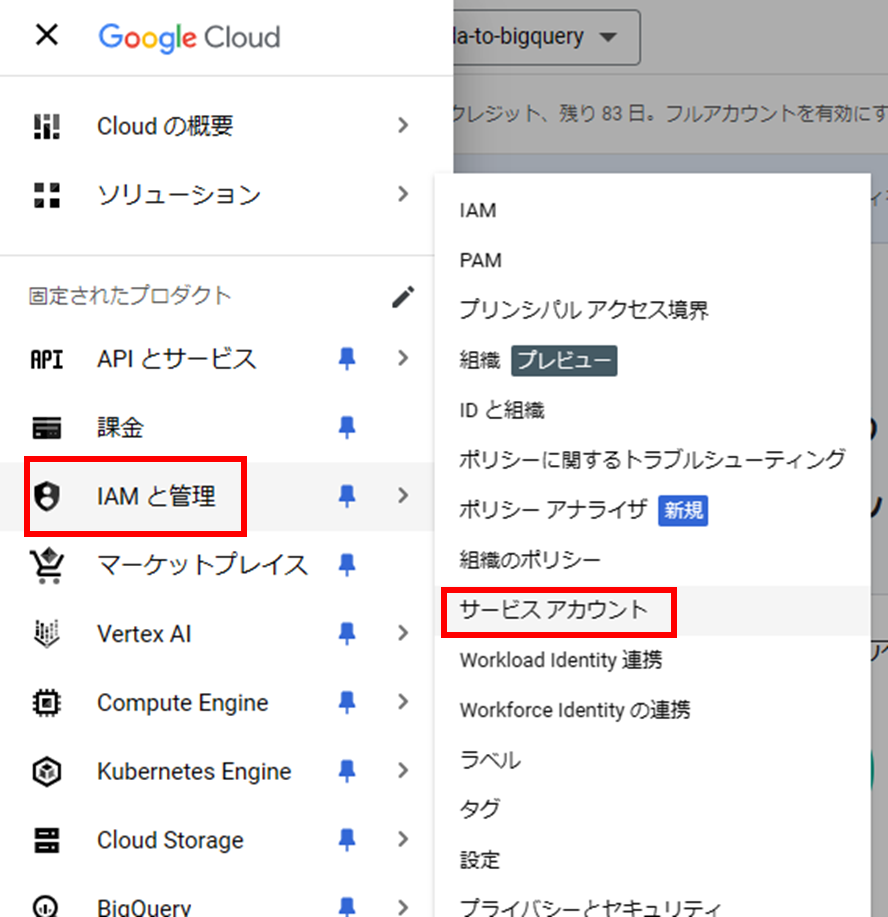
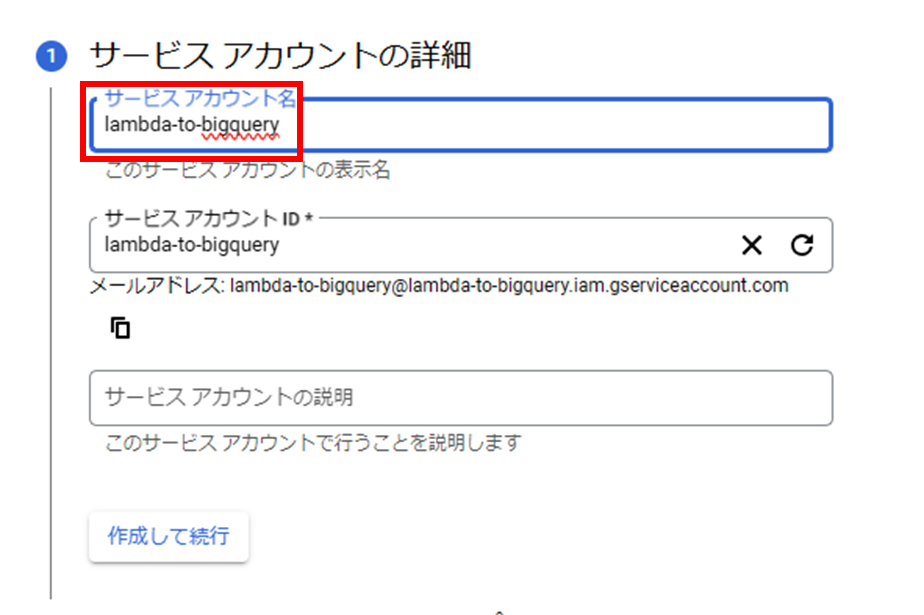
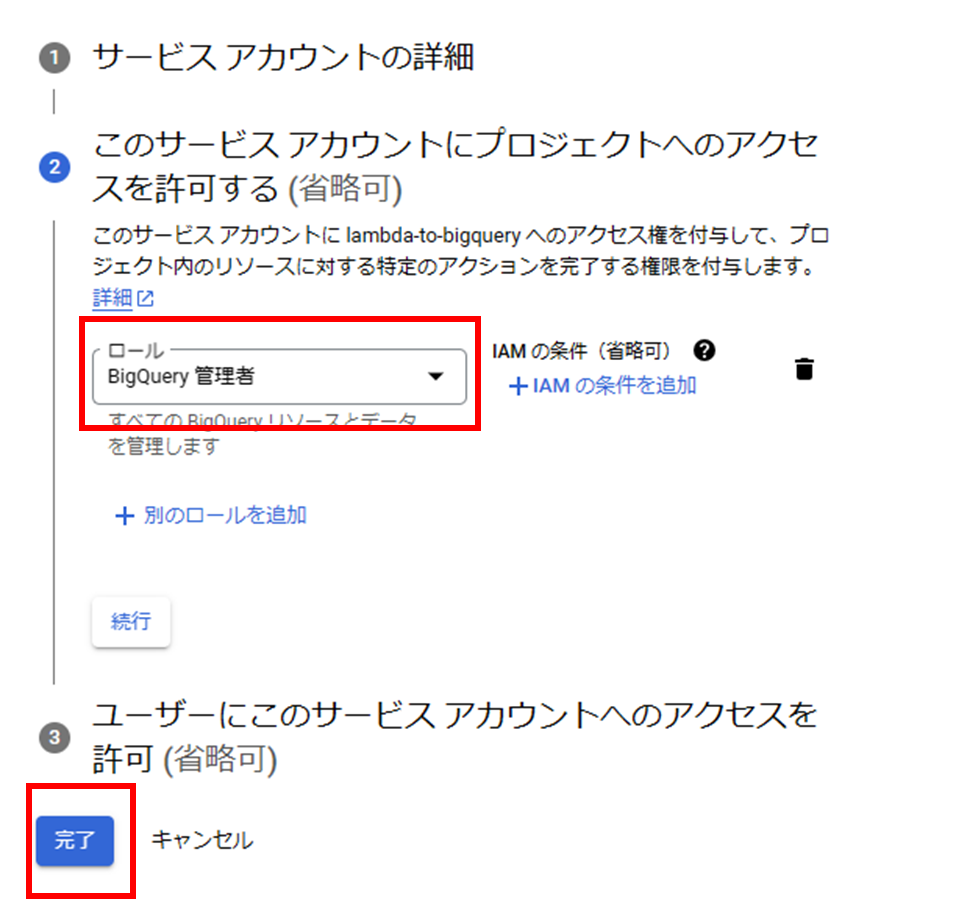
- サービスアカウントを作成をクリックし以下を設定して完了を押す:
- サービスアカウント名: lambda-to-bigquery
- ロール: BigQuery 管理者
2. 認証情報のダウンロード:
- 作成したサービスアカウントの詳細画面に移動
- 鍵 > キーを追加 > 新しい鍵を作成
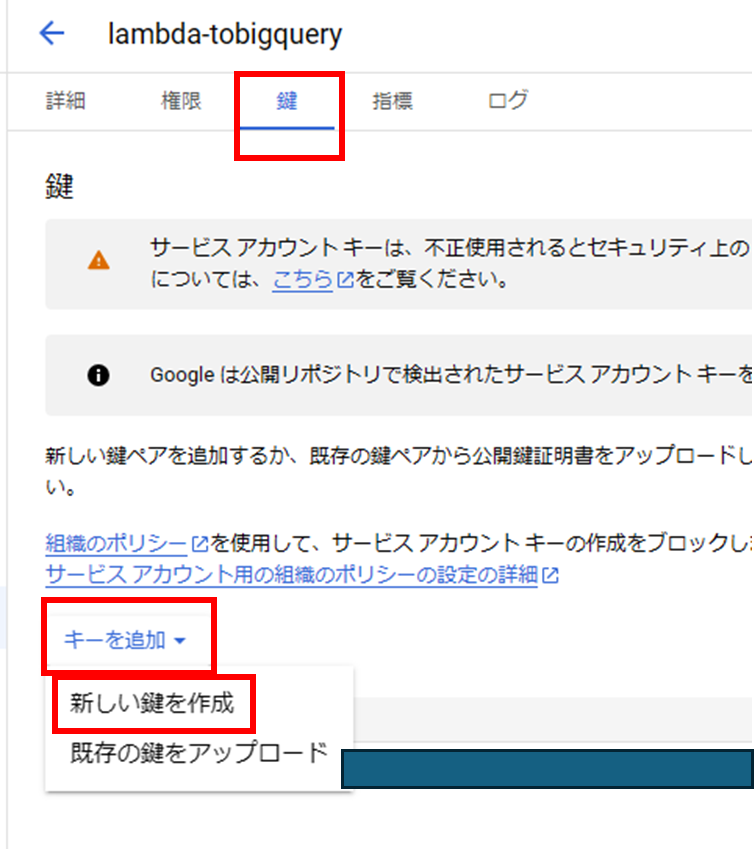
- キーのタイプ: JSON

- 作成をクリックするとJSONファイルがダウンロードされます
AWSでのパラメータストアの設定
- Parameter Storeの設定:
- AWS Systems Managerコンソールを開く
- 左メニューからパラメータストアを選択
- パラメータの作成をクリック
- 以下の項目を入力:
- 名前: /gcp/bigquery/credentials
- タイプ: SecureString
- 値: ダウンロードしたGCPサービスアカウントのJSONキーの内容をそのまま貼り付け
- パラメータの作成をクリック
AWS Lambda関数の作成
- Lambda関数の作成:
- AWS Lambdaコンソールで新しい関数を作成します:
- 関数名: lambda-to-bigquery
- ランタイム: Python 3.12
2. 必要なライブラリのインストール:
i. ローカル環境でLambda Layer用のパッケージを作成:
# 作業ディレクトリの作成
$ mkdir -p lambda-layer/python
$ cd lambda-layer
# 必要なライブラリのインストール
$ pip install google-cloud-bigquery -t python/
# ZIPファイルの作成
$ zip -r ../lambda-layer.zip python/ii. Lambda Layerの作成:
- AWSコンソールでレイヤー > レイヤーの作成を選択
- 以下の項目を入力:
- 名前: lambda-to-bigquery-layer
- .zip ファイルをアップロード: 作成したlambda-layer.zipをアップロード
- 互換性のあるランタイム: Python 3.12
- 作成をクリック
iii. Lambda関数へのLayer追加:
- lambda-to-bigqueryのLambdaの画面に移動し、コードタブを選択したまま一番下までスクロールし、レイヤーの追加をクリック
- 以下の項目を入力:
- レイヤーソース: カスタムレイヤー
- カスタムレイヤー: bigquery-layer
- バージョン: 1
- 作成をクリック
3. タイムアウト時間の変更:
- 設定 > 一般設定 > 編集 をクリック
- タイムアウト時間を1分に変更し保存をクリック
4. IAMロールの設定:
Parameter Storeからパラメータを取得するための権限ssm:GetParameterの権限を付与します
- lambda-to-bigqueryのLambdaの画面で設定 > アクセス権限 > ロール名 の順に選択
- IAMロールの画面に遷移するので、許可を追加 > インラインポリシーの追加
- ポリシードキュメント:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "ssm:GetParameter",
"Resource": "*"
}
]
}- ポリシー名: lambda-to-bigquery-ssm-get-parameter-policy
- ポリシーの作成をクリック
5. Lambda関数のコードをデプロイ:
- lambda-to-bigqueryのLambda関数の画面に移動し、以下コードを貼り付け、Deployをクリック
"""
BigQueryテーブル作成・データ挿入Lambda関数
このスクリプトは、AWS LambdaからGCP BigQueryにアクセスし、
日付サフィックス付きのテーブルを作成してデータを挿入します。
Requirements:
- google-cloud-bigquery
- boto3
Environment Variables:
- PARAMETER_NAME: AWS Parameter Storeのパラメータ名
"""
import os
import json
import time
import boto3
from google.cloud import bigquery
from datetime import datetime
from typing import List, Dict, Any
def get_credentials() -> Dict[str, Any]:
"""
AWS Parameter Storeから認証情報を取得します。
Returns:
Dict[str, Any]: GCPサービスアカウントの認証情報
"""
ssm = boto3.client('ssm')
parameter_name = os.environ.get('PARAMETER_NAME', '/gcp/bigquery/credentials')
parameter = ssm.get_parameter(Name=parameter_name, WithDecryption=True)
return json.loads(parameter['Parameter']['Value'])
def create_dataset_if_not_exists(client: bigquery.Client, dataset_id: str) -> None:
"""
指定されたデータセットが存在しない場合、新しいデータセットを作成します。
Args:
client: BigQueryクライアント
dataset_id: 作成するデータセットのID
"""
try:
client.get_dataset(dataset_id)
print(f"データセット {dataset_id} は既に存在します。")
except Exception as e:
dataset = bigquery.Dataset(dataset_id)
dataset.location = "US" # データセットのロケーションを設定
client.create_dataset(dataset)
print(f"データセット {dataset_id} を作成しました。")
def create_table_if_not_exists(client: bigquery.Client, table_name: str) -> None:
"""
指定されたテーブルが存在しない場合、新しいテーブルを作成します。
Args:
client: BigQueryクライアント
table_name: 作成するテーブルの完全修飾名
"""
try:
client.get_table(table_name)
print(f"テーブル {table_name} は既に存在します。")
except Exception as e:
schema = [
bigquery.SchemaField("user_id", "STRING"),
bigquery.SchemaField("name", "STRING"),
]
table = bigquery.Table(table_name, schema=schema)
client.create_table(table)
print(f"テーブル {table_name} を作成しました。")
print("テーブルの作成完了を待機中...")
time.sleep(10) # テーブル作成完了を待つために10秒待機
print("待機完了")
def insert_data(client: bigquery.Client, table_name: str, rows: List[Dict[str, str]]) -> None:
"""
テーブルにデータを挿入します。
Args:
client: BigQueryクライアント
table_name: テーブルの完全修飾名
rows: 挿入するデータの行のリスト
"""
errors = client.insert_rows_json(table_name, rows)
if errors:
raise Exception(f"データの挿入中にエラーが発生しました: {errors}")
print("データが正常に挿入されました。")
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict[str, Any]:
"""
Lambda関数のメインハンドラー
Args:
event: Lambda関数のイベントデータ
context: Lambda関数のコンテキスト
Returns:
Dict[str, Any]: 実行結果
"""
try:
# BigQueryクライアントの作成
credentials = get_credentials()
client = bigquery.Client.from_service_account_info(credentials)
# プロジェクトIDとデータセットIDの設定
project_id = credentials.get('project_id')
dataset_id = f"{project_id}.test_data_set"
# データセットの作成
create_dataset_if_not_exists(client, dataset_id)
# テーブル名の生成
today = datetime.now().strftime('%Y%m%d')
table_name = f"{dataset_id}.test_table_{today}"
# テーブルの作成
create_table_if_not_exists(client, table_name)
# テストデータの定義
test_data = [
{"user_id": "test001", "name": "テストユーザー1"},
{"user_id": "test002", "name": "テストユーザー2"},
{"user_id": "test003", "name": "テストユーザー3"},
{"user_id": "test004", "name": "テストユーザー4"},
{"user_id": "test005", "name": "テストユーザー5"},
]
# データの挿入
insert_data(client, table_name, test_data)
return {
'statusCode': 200,
'body': json.dumps('処理が正常に完了しました。')
}
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps(f'エラーが発生しました: {str(e)}')
}実行
- テストタブを選択し、以下を設定
- イベント名: test
- テストをクリック
- 実行中の関数: 成功が表示されれば成功です
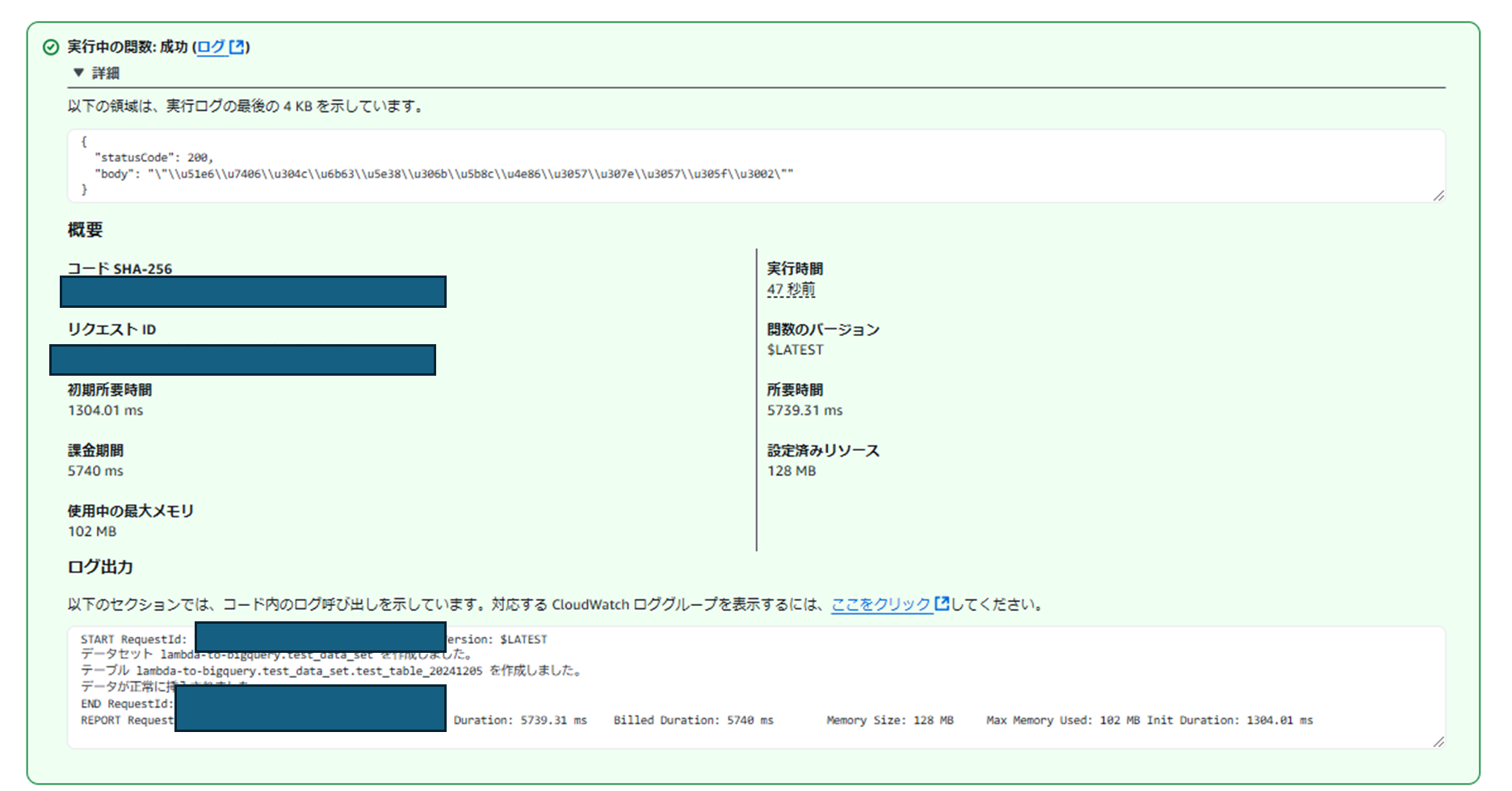
確認
- Google Cloud Consoleから BigQuery をクリック
- プロジェクト名 > test_data_set > test_table_(1) が作成されていると思います
- test_table_(1) をクリックし、プレビューをクリックするとデータが挿入されていることが確認できます

まとめ
Google Cloudで認証情報を利用してLambdaからBigQueryにデータを挿入することができました
おわりに
初めてGoogle Cloudを触りましたが、このやり方を知っていればいろんなサービスをAWSから利用できそうですね
今後も参考になりそうなので、この機会に勉強することができて良かったです!
この記事をシェアする

関連記事
-
 AWS Security HubとBedrock AIで実現するセキュリティ通知システム
AWS Security HubとBedrock AIで実現するセキュリティ通知システム -
 AWS LambdaのKotlinからログをJSONでいい感じに出す
AWS LambdaのKotlinからログをJSONでいい感じに出す -
 【Hono】HonoとAWS Lambdaを使った開発の第一歩
【Hono】HonoとAWS Lambdaを使った開発の第一歩